af
H. B. Hansen
Objektorienteret programmering har været på den datalogiske skueplads meget længe - faktisk helt fra 1967, hvor programmeringssproget Simula blev konstrueret. Hvad er da grunden til at den objektorienterede tankegang først nu finder tilslutning, ja bliver til det store dyr i åbenbaringen? Dette spørgsmål kan jeg faktisk ikke svare på, for jeg har selv følt mig tiltrukket af den objektorienterede tankegang siden jeg først hørte om den, omkring 1970, og har undervist i objektorienteret programmering siden 1972 på Roskilde Universitetscenter. Måske er der tale om en modningsproces der kun kan forstås hvis man ser på den historiske udvikling af vores fag på det programmeringsmæssige område.
I 1957, da jeg startede min datalogiske løbebane, tænkte jeg ikke på progammering som en intellektuel, kreativ aktivitet. Programmering var et spørgsmål om teknik; det gjalt om at indstille eller trimme en elektronregnemaskine (som det hed dengang) så den løste en bestemt opgave når man trykkede på startknappen. Mit billede af maskinen svarede nærmest til det vi i dag har af en lommeregner: et apparat der kan regne hurtigt og sikkert. Der var blot den forskel at alle de knapper der er på lommeregneren var hvad vi i dag kalder "virtuelle"; de fandtes ikke i virkeligheden, men programmering bestod i at specificere hvilke knapper man ville have trykket på hvis de havde fandtes.
Dette billede var godt nok i starten, men ikke ret længe. Snart blev de programmer der skulle udarbejdes så omfattende at trykknapmetaforen brød sammen. Som vi ved var det ikkeblot for mig dette skete, det var en generel erfaring, som resulterede i de højere programmeringssprog. Nu var det hele maskinender blev virtuel, og ikke blot trykknapperne.
En af vanskelighederne ved den simple trykknapmodel var at der ikke fandtes typer - eller rettere: der var kun én type: celler i et lager, bestående af bits. Alt måtte på en eller anden måde repræsenteres som bits i celler. Når man så på indholdet i lageret var det blot bits, og det var umuligt at bestemme meningen med dette indhold på anden måde end ved at referere til en ekstern fortolkning. Det gav anledning til alt for mange fejlmuligheder. Indførelsen af typer i de højere programmeringssprog var et stort fremskridt. Til hver datatype kunne associeres visse tilladte operationer, og nu blev det derfor muligt at lade maskinen selv kontrollere om man specificerede meningsløse operationer i sine programmer. Der kom semantik ind i programmeringssprogene.
Indførelse af typer er ikke begrænset til Datalogien, men er en helt generel metode som vi mennesker bruger til at få orden i kaos. Tænk blot på biologernes omfattende typesystem for alt liv på jorden, eller lægernes sygdomskategorier. Det er nærmest umuligt at forestille sig menneskehedens udvikling, hvis ikke mennesket havde haft denne naturlige evne til at kategorisere fænomenerne i dets omgivelser. Mange af de typesystemer vi arbejder med til daglig, er uhyre komplekse hierarkiske systemer, med typer og undertyper i mange lag. Kategoriseringer noget vi mennesker er gode til.
Set i forhold hertil er de typesystemer der arbejdes med i fleste højere programmeringssprog uhyre primitive. Der er nærmest kun ét lag med ganske få forskellige typer: hele tal, reelle tal, tegn og logiske størrelser, samt ordnede mængder af disse i form af arrays og tekster. Det er måske derfor ikke mærkeligt at der er nogle der har tænkt at det var en god idé at gå videre, og opbygge mere komplekse typer også i datalogisk sammenhæng. Med lidt god vilje kan man opfatte procedurebegrebet i de højere sprog som en måde at realisere programmerede typer på, men det ultimative begreb er nok det der kaldes abstrakte datatyper.
Inden jeg går videre med de abstrakte datatyper vil jeg nærme mig den objektorienterede tankegang fra en anden retning, idet jeg vil filosofere lidt over hvordan vi mennesker tackler problemer til daglig. Hvis min bil fx går i stykker, så har jeg et problem. Hvad gør jeg for at løse dette problem? Jeg henvender mig på et bilværksted og forklarer dem hvori problemet består. Så overlader jeg bilen til værkføreren for værkstedet og får den udleveret i repareret tilstand nogen tid efter.
Hvad er det jeg har gjort for at få løst mit problem? Jeg har fundet en passende agent eller udbyder af service, som jeg har overbragt en meddelelse om mit problem. Det er så blevet denne agents ansvar at løse problemet på mine vegne. Han har en eller anden metode til at løseproblemet, men den behøver jeg ikke at kende til. Hvis jeg var nysgerrig og forskede lidt i hvilken metode værkføreren brugte, ville jeg måske opdage at han overbragte en meddelelse (måske lidt transformeret i forhold til min oprindelige meddelelse) til en anden agent, måske en automekaniker, og at der først da faktisk skete noget fysisk med min bil.
Den samme fremgangsmåde benytter jeg i utallige andre situationer.Hvis jeg skal sende en buket blomster til min tante i Thisted, fx, så henvender jeg mig til min lokale blomsterhandler med en meddelelse der indeholder information om hvilke blomster jeg ønsker, samt min tantes adresse, og så sker det hele bag kulisserne, formodentlig ved at blomsterhandleren videregiver min meddelelse til en anden blomsterhandler i Thisted, der så sørger for at fremskaffe blomsterne, binde en buket, og få den sendt ud til min tante. Der er en lang række af meddelelser og agenter, måske spredt over lange tidsrum, før min tante modtager buketten. Den fysiske realitet, buketten, stammer til syvende og sidst fra gartneren der dyrker blomsterne, men han er næsten helt forsvundet i de overvejelser jeg gør mig når jeg tænker på at give min tante blomster.
Men agenternes valg af metode er som sagt ikke mit problem. Tværtimod ville jeg næsten sige, for der ligger en stor fleksibilitet i den omstændighed at jeg overhovedet ikke blander mig i blomsterhandlerens eller værkførerens metoder; de er fri til at vælge hvilken teknik de finder for godt, blot de leverer løsningen på problemet.
Agenten er modtageren af min meddelelse. Han er en nødvendig betingelse for at problemet bliver løst. Hver agent har sine metoder, som er specifikke for netop den service han kan tilbyde. Hvis jeg havde henvendt mig til værkføreren med mit blomsterproblem, ville han formentlig have udsendt en eller anden fejlmeddelelse der sagde at han ikke havde nogen egnet metode til at løse dette problem.
Denne generelle måde at løse problemer på har en klar relation til typebegrebet. Værkføreren og blomsterhandleren svarer til "variable" for, eller instancer af, to typer: bilværksteder og blomsterforretninger. Bilværksteder og blomsterforretninger er samlebegreber der omfatter alle de individuelle næringsdrivende i disse brancher. I den objektorienterede begrebsverden kaldes sådanne overordnede begreber for klasser, og de enkelte individuelle instancer af disse klasser kaldes for objekter. Objektorienteret programmering tager sigte på at overføre og efterligne denne "ansvarsdelegerende" problemløsningsmetode til dataprocesser.
En af fordelene ved objektorienteret programmering er denne benyttelse af metaforer fra dagligdagen. Når en programmør tænker på sit program som nogle objekter, der opfører sig på bestemte måder og har visse ansvar at leve op til, så kan han trække på et væld af erfaringer fra dagligdagen, og herved få ideer til strukturering af det samlede program; ideer som ikke på samme selvfølgelige måde melder sig, hvis han tænker i termer af hylder i et lager der indeholder værdier, og postkasser der kan bruges til at overføre værdier fra hylde til hylde.
Nu er det nok på tide at se lidt nærmere på et konkret objektorienteret programmeringssprog. Her vil jeg benytte sproget C++. Det er et sprog i Algolfamilien, hvortil også et sprog som Pascal hører. C++ er en ægte overmængde af sproget C, forstået sådan at et program skrevet i C kan oversættes som om det var et C++ program. Det nye der er kommet til, er klassebegrebet, som gør det muligt at definere nye typer i sproget.
Lad os se på en erklæring af en simpel klasse i C++:
enum sexType {girl,boy};
class person
{
private:
sexType s;
int a;
person* sibling;
public:
person(sexType sex, int age = 0)
{
assert(age >= 0); //en alder skal være positiv
s = sex; a = age; sibling = 0;
}
sexType sex() { return s; }
int age() { return a; }
person& a_sibling() { return *sibling; }
void birthday() { a++; }
};
Denne klasse kan opfattes som en generel beskrivelse af personer. Kun de
egenskaber ved personer der har interesse i den givne opgave er medtaget
i beskrivelsen. Det hænder sig at være personens køn
(s), alder (a) og søskende (sibling).Disse såkaldte attributter
er noget meget personligt for en person, og dem må omgivelserne ikke
pille ved; derfor er de erklæret som private, hvorved de er
skjult for det omgivende program. En person er dog villig til at meddele
værdierne af attributterne til omverdenen; det sker via funktionerne
sex(), age() og a_sibling(). Disse funktioner er offentlige (public)
og kaldes metoder.
En person kan have fødselsdag. En fødselsdag giver sig udslag i at alderen forøges med 1. Alderen kan altså godt påvirkes udefra, vha. metoden birthday(), men kun i spring på 1. Det er derfor umuligt at sætte alderen til fx -37.
For at denne klasse skal kunne nyttiggøres kræves der at man kan danne konkrete personer ud fra klassen. Sådanne konkrete personer kaldes objekter. Hvis man fx skriver:
person Peter(boy);så sker der det at der skabes en dreng ved navn Peter. Teknisk set er det en variabel af typen person med navnet Peter, og skabelsen sker ved at metoden person (den såkaldte konstruktør) i klassen person kaldes med aktuel parameter boy. Parameteren age behøver ikke at angives, for den har erstatningsværdien 0. Peter fødes altså med alder 0. Værdien afsibling er 0, hvilket skal betyde at Peters søskende er ubekendte.
Indtil dette punkt ligner en klasse meget det recordbegreb der kendes fra Pascal. Forskellen viser sig i metoderne - de procedurer der er erklæret i klassekroppen. Ligesom for en record kan man adressere attributterne ved hjælp af priknotation, og det gælder også for metoderne. Peters alder kan derfor findes som værdien af udtrykket:
Peter.age();Dette udtryk skal opfattes som en forespørgsel til objektet Peter om at afsløre sin egen alder, a. Ændring af a kan kun ske via metoden birthday; sætningen:
Peter.birthday();vil bevirke at Peters a bliver én større.
Selv dette simple eksempel viser mange af de muligheder der ligger i den objektorienterede programmeringsstil. I denne stil er data og algoritmer ikke adskilt, men derimod knyttet sammen ved hjælp af klassebegrebet. Man kan skjule eller indkapsle selve datastrukturen, og man kan også, ved hjælp af metoderne, definere lovlige operationer på tilstanden af et objekt.
Lad mig på dette sted filosofere lidt over forskellen mellem denne programmeringsstil og den stil man finder i procedureorienterede sprog som Pascal. I Pascal ville man finde Peters alder vha. et funktionskald af formen:
age(Peter);Der er altså en forskel i selve den syntaktiske form, og jeg mener at dette har nogle psykologiske konsekvenser. Pascalnotationen giver udtryk for at Peter underkastes en proces, mens notationen Peter.age() er udtryk for en forespørgsel til Peter. I første tilfælde er det svært at opgive forestillingen om, at det er det kaldende program der så at sige bestemmer farten, mens den anden syntaks ikke i samme grad forudsætter at kalderen ved hvordan man tilfredsstiller forespørgslen.
Hvis man følger reglen om at udtryk evalueres fra venstremod højre, så vil age(Peter) bevirke at age fortolkes først, hvorved der skabes en forventning om at der kommer et argument af typen person. Fortolkning af Peter før age vil derimod bevirke at age fortolkes i konteksten for en person, eller sagt på en anden måde, at funktioner anskues som egenskaber ved dataobjekter. Det er derfor rimeligt at kalde age(Person) for en procedureorienteret syntaks, og Person.age() for en objektorinteret syntaks. Set i et pædagogisk perspektiv har denne forskel efter min mening stor betydning.
Men foreløbig er systemet "flat" i den forstand at hver klasse er "sig selv", uafhængig af andre klasser. Det næste skridt er at indføre klassehierarkier; det gøres ved hjælp af nedarvning. Lad os definere begrebet "en mor" som en særlig slags "person":
class mother: public person
{
private:
person* my_children;
public:
mother(int age = 0): person(girl,age) {}
person* firstChild() { return my_children; }
person birth(sexType sex)
{
person* baby = new person(sex);
baby->a_sibling() = *my_children;
my_children = baby;
return *baby;
}
};
Denne klassedefinition udtrykker at en mor arver alle en persons attributter
og metoder. En mor er altså en speciel form for person, der har nogle
ekstra attributter og metoder (nemlig en reference til moderens børn,
my_children, og en evne til at føde et barn, birth()).
Metoderne i den klasse mother arver fra, er tilgængelige fra et mother-objekt. Hvis man fx skriver:
mother Marie(15);så skabes der et mother-objekt ved navn Marie, og med alder15. Nu kan vi fx anvende metoderne i objektet Maries overklasse person således:
while (Marie.age < 20) marie.birtday();som kunne være en simulation af at Marie bliver ældre. Nu er Marie altså 20 år. Lad os tænke os at hun på dette tidspunkt føder Peter:
Peter = Marie.birth(boy);Dette kald af metoden birth i objektet Marie vil returnere et nyt person-objekt (fordi proceduren birth teknisk set er en funktion), men som sidevirkning vil der ske det, at en kopi af objektet sættes ind i en kø af person-objekter, som attributten my_children peger på. Ved denne kødannelse bruges attributten sibling i klassen person (de tekniske detaljer er ganske uinteressante), som vist i kroppen af birth. Dette eksempel viser altså dels nedarvning, men også lidt om hvordan dynamiske datastrukturer kan konstrueres i et objektorienteret sprog.
Hvad har vi opnået i forhold til fx units i Turbo Pascal? Faktisk ikke meget. En unit er også en mekanisme til at fremstille abstrakte datatyper med følgende egenskaber:
1. At kunne eksportere typedefinitioner.
2. At stille operationer til rådighed, som kan bruges til at manipulere instancer af typen.
3. At beskytte data associeret med typen imod utilsigtede ændringer.
4. At fremstille multiple instancer af typen.
Men hvorfor så overhovedet bruge det objektorinterede programmeringsparadigme? Ja, en af grundene har jeg allerede nævnt, nemlig den psykologiske, men der er også en anden grund, og den hænger sammen med begrebet polymorfisme.
Det er almindelig kendt i datalogiske kredse at man kan evaluere aritmetiske udtryk ved omskrivning til omvendt polsk notation, og anvendelse af en stak. Det er den procedureorienterede måde at gøre det på. Som objektorienteret programmør vil man måske mere føle sig tiltrukket af den tanke at et aritmetisk udtryk kan repræsenteres som et træ hvor knuderne er enten operatorer eller operander. Knuder i et træ er oplagte objektkandidater. For ikke at gøre eksemplet for kompliceret vil jeg indskrænke mig til at behandle dyadiske operatorer: addition, subtraktion, multiplikation og division. Nedenfor ses en skitse af et system af klasser der kan bruges til evaluering af aritmetiske udtryk der er repræsenteret i en binær træstruktur.
class node
{
public:
virtual float eval() = 0;
};
class value_node: public node
{
private:
float a_number;
public:
float eval() { return a_number; }
};
class interiour_node: public node
{
private:
node *left,*right;
public:
virtual float eval() = 0;
};
class plus: public interior_node
{
public:
float eval()
{ return left->eval() + right->eval(); }
};
class minus: public interiour_node
{
public:
float eval()
{ return left->eval() - right->eval(); }
};
class times: public interiour_node
{
public:
float eval()
{ return left->eval() * right->eval(); }
};
class diveded: public interiour_node
{
public:
float eval()
{ return left->eval() / right->eval(); }
};
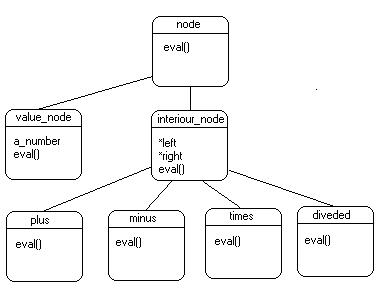
Dette system af klasser kan afbildes grafisk i et klassehierarki som vist
på figur 1.
Fig. 1 Diagram over klassehierarkiet for aritmetiske beregninger.
Disse klasser modellerer operander og operatorer i et aritmetisk
udtryk. Klassen node er en fælles superklasse, som alle de øvrige
klasser arver fra (direkte eller indirekte). Den er faktisk tom, idet det
eneste der nævnes er, at dens arvinger alle vil definere en metode
ved navn eval(), der returnerer en værdi. Dette løfte afgives
ved at specificere metoden som en virtuel metode.
Klassen value_node repræsenterer en konstant (et reelt tal),og den definerer en konkret udgave af eval(), der simpelthen returnerer denne konstants værdi.
Klasserne plus, minus, times og diveded repræsenterer de fire regningsarter. De arver alle fra en fælles overklasse, interiour_node, der definerer to pegere, en til venstre undertræ og en til højre undertræ (hhv. left og right). Herudover har alle klasserne en konkret udgave af eval(), der returnerer resultatet af den beregning som klassen repræsenterer.
Det interessante er arvehierarkiet i dette system af klasser. Alle klasserne arver som sagt fra node. Man kan sige at det eneste underklasserne arver er klassemedlemskabet af node. Men det gør at de alle kan indsættes i den samme datastruktur, fx et binært træ. Det er derfor at attributterne left og right er erklæret som node*. Der er altså fx ikke taget stilling til om venstreoperanden eller højreoperanden for et givet plus-objekt er et value_node-objekt eller et andet operator-objekt.
Fidusen er, at en virtual-specifikation i en overklasse vil bevirke, at det er den konkrete funktion der ligger dybest i arvehierarkiet, der vil blive anvendt, in casu alle de metoder der ligger i arvingerne til node og interiour_node.
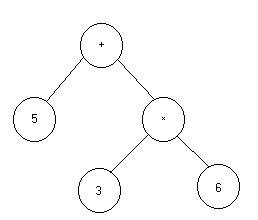
Fig. 2. Et træ til beregning af udtrykket 5 + 3*6.Knuderne repræsenterer objekter og ikke klasser som på figur 1.
Et program der beregner værdien af udtrykket X := 5 + 3*6,kan
repræsenteres som træet på figur 2. Her er tree erklæret
som en node. Evalueringen af udtrykket kan ske ved kaldet:
X = tree.eval();Tree peger på et plus-objekt, og dette objekts left og right er henholdsvis et value_node objekt med number = 5, og et times objekt. Tree.eval() bliver derfor 5 plus værdien af times-objektets eval, som ses at blive 3*6.
Den skitserede teknik med anvendelse af virtuelle metoder kaldes polymorfisme. Begrebet kendes også fra ikke-objektorienterede sprog, hyppigst i form af "overloading" af de aritmetiske operatorer, således at man fx kan addere reals og integers uden først at konvertere alle integers til real. De sprog hvor en sådan typekonvertering kræves (Ada fx) kaldes monomorfe.
Hvad opnår man ved at konstruere programmer efter objektorienterede principper? Tjah, i teorien er de fleste software engineering problemer løst. Man får et program der er modificerbart, og som består af stumper der kan genanvendes.
Lad mig tage genanvendelsen først. At kunne genanvende programmer eller dele af programmer har været en drøm i mange år. Genanvendelse er en nødvendig forudsætning for en økonomisk overkommelig udvikling af store programsystemer. Allerede i 1968 rejste McIlroy problemet, ved at gøre opmærksom på det ejendommelige forhold at produktion af programmel ikke er industrialiseret på samme måde som fx masseproduktion af datamater eller biler, som jo går ud på at man benytter underleverandører til de enkelte komponenter i en større konstruktion, efter principper der er helt analoge med dem jeg har nævnt i mine eksempler om dagligdags problemløsning.
Hvad er det mon der gør det nødvendigt at programmere næsten den samme rutine for opslag i en tabel om og om igen i hver eneste applikation? Det svarer nærmest til at man selv skulle skære gevind i hver skrue i stedet for at købe en æske skruer hos isenkræmmeren. Det må på en eller anden måde skyldes manglende standardisering, hvilket nok igen bunder i manglende forståelse af problemet, og dermed usikkerhed om hvordan det kan abstraheres og parametriseres.
Jeg vil ikke påstå at objektorientering skaber øget forståelse i sig selv, men det giver en hensigtsmæssig ramme for ens bestræbelser for at standardisere, hvilket i denne forbindelse vil sige at skabe abstrakte datatyper. Alligevel viser erfaringerne at det er meget vanskeligt at gøre sine abstrakte datatyper så abstrakte at de slet ikke knytter sig til nogen bestemt applikation. De hyppigst citerede eksempler i lærebøger og artikler drejer sig om stakke og køer og den slags meget generelle datastrukturer, men hvad - det er da et stykke på vejen. På en måde er det mærkeligt at man næsten aldrig ser fx kalenderberegninger brugt som eksempel; det er jo en oplagt kandidat til en abstrakt datatype. Tænk at kunne lægge et antal dage til en dato, og få en ny dato ud af det, uden at skulle bekymre sig om månedsskift eller årsskift, og med skyldig hensyntagen til skudår og sekularår! Måske skyldes det at heller ikke lærebogsforfatterne kan programmere denne abstrakte datatype fejlfrit.
Hvad angår modificerbarheden, så er anvendelse af polymorfisme helt klart en stor hjælp. Det er fx ikke noget større problem at indføre monadiske operatorer i eksemplet med evaluering. Alt hvad der kræves for at indføre fx kvadratrod er en ny klasse i evaluation, med følgendestruktur:
class squareroot: public node
{
private:
node* operand;
public:
float eval() { return sqrt(operand->eval()); }
};
Alt andet er uændret. Tænk hvilke ændringer der ville
være nødvendige hvis det havde drejet sig om den procedureorienterede
teknik med omvendt polsk notation. Så kunne man selvfølgelig
tænke sig en procedureorienteret realisation, der ligner den foreliggende,
med en træstruktur, men her kommer man heller ikke uden om at skulle
ændre i det eksisterende program, fx ved at tilføje et nyt
tilfælde til en case-konstruktion. Med andre ord: objektorienterede
programmer er udvidelige.
For god ordens skyld vil jeg lige nævne, at denne udvidelse med kvadratrod viser en designfejl i hele systemet. Som det er nu må alle monadiske operatorer have en individuel peger til deres operand. Det havde været bedre at dele interiour_node i to: dyadic_node og monadic_node med virtuelle eval-metoder. Så ville indførelse af sinus og cosinus, monadisk plus og minus, og hvad man ellers kan finde på, have fulgt samme melodi som for de dyadiske operatorer. Dette viser en anden side af kunsten at konstruere abstrakte datatyper: det er svært at være generel nok!
Den opmærksomme læser vil måske sidde med en ubehagelig mistanke om, at skabelsen af et træ som figur 2 tvinger os tilbage til den gammeldags metode med omvendt polsk notation og stak. Hvad skal det hele så være godt for? Jo, skabelsen skal kun ske én gang, mens evalueringen måske skal udføres mange gange. Det er fx tilfældet i forbindelse med regneark.
Vi er nu kommet fra den typeløse verden i maskinprogrammering, til programmeringssprog hvor det er muligt at programmere sine egne typer. Måske kræver denne udvikling et tidsforløb på 30-40 år før den er absorberet af størstedelen af det datalogiske samfund. Men ét er at være opmærksom på muligheden af objektorienteret programmering, og noget andet er at skrive velformede objektorienterede programmer. Det skal sidste del af dette skrift handle om.
Der findes en mængde objektorienterede systembeskrivelses- og systemkonstruktionsmetoder, med hver sine konventioner for angivelse af klasser og metoder, ofte i form af særlige signaturer. De fleste af disse metoder markedsføres som om anvendelsen af denne særlige metode gør fremstilling af objektorienterede programmer til en blot og bar rutinesag. En af de påstande man hyppigt hører i forbindelse med sådanne metoder er at brugerdeltagelsen bliver lettere at realisere, fordi de to parter, brugeren og systemudvikleren, kan tale samme sprog; objekterne knytter sig intimt til selve problemstillingen, og man kan bruge objektbetegnelser som brugeren genkender fra sit manuelle system. Man skal altså forsøge at simulere det reelle system så tæt som muligt. Dette er en sandhed med modifikationer, og det vil jeg forsøge at demonstrere med et sidste, meget forenklet eksempel, et lønudbetalingsprogram.
Der er to slags ansatte: faste og løse medarbejdere. De faste medarbejdere får fast ugeløn, mens en løs medarbejder får fast timeløn. Faste medarbejdere får også løn i sygdomsperioder, mens løse medarbejdere kun får løn for det faktiske antal timer; sygdomsperioder registreres dog for begge medarbejderkategorier. Til gengæld må faste medarbejdere arbejde over uden ekstra løn, mens løse medarbejdere får ekstra1/2 gange timelønnen pr. time for overarbejde. Det er overladt til den enkelte medarbejders nærmeste chef at holde styr på opsparet og afholdt ferie.
Forretningsgangen kan skitseres således:
Begge kategorier af medarbejdere udfylder timesedler en gang om dagen, og disse timesedler indsamles hver fredag. Mandag morgen gennemgås de indsamlede timesedler, og anbringes i en hængemappe for hver medarbejder, hvori der desuden findes oplysninger om medarbejderens navn, adresse, bankkonto m.v. Under gennemgangen adderes timetallene til en liste over totaltimetallet for hver medarbejder pr. uge. For faste medarbejdere indføres blot 40 timer minus sygetimer på denne liste. Hvis en medarbejder har holdt ferie i vedkommende uge anføres blot "ferie" på listen.
Om tirsdagen beregnes lønnen for hver medarbejder, og de nødvendige formularer for indsættelse af lønnen på medarbejdernes bankkonto udfyldes og underskrives. Ved samme lejlighed føres en liste med medarbejdernes navne, samt akkumulerede timetal og løn for år til dato. Denne liste kan bruges ved bestemmelse af om en medarbejder har ferie tilgode.
Ledelsen af virksomheden ønsker en tættere styring af ferieregnskabet og selve lønberegningen, og programmet skal laves sådan at det let kan udvides til andre kontoradministrative opgaver.
Følger man rådet om at simulere det eksisterende system så tæt som muligt kan man let komme op med en liste over objekter med tilhørende attributter og metoder af omtrent følgende art:
* Medarbejder
- udfylder timeseddel
* Timeseddel
- indeholder timetal
* Lønpost
- indeholder ugeløn/timeløn, timetal, feriedata m.v.
* Timeregistrator (model af hængemappesystemet)
- henter timetal fra timeseddel og indsætter i lønpost.
- genererer timetalsrapport og beder den om at trykke sig selv.
* Timetalsrapport
- kan trykke sig selv.
* Lønberegning (model af kontordamen i lønningsbogholderiet)
- udfører lønberegning ud fra lønpost.
- genererer bankformular.
* Bankformular
- kan trykke sig selv.
* Lønregistrator
- beordrer løberegning udført og trykning af tilhørende bankformular.
- genererer år-til-dato rapport og beder den om at trykke sig selv.
* År-til-dato rapport
- kan trykke sig selv.
Dette er ikke nogen god objektorienteret model. Der er for mange forskellige klasser, og de kan for lidt hver især. De enkelte objekter for hver klasse skal vide alt for meget om hinanden, så der bliver en masse kommunikation mellem forskellige objekter i denne model. Man kunne egentlig lige så godthave lavet en traditionel procedureorienteret model. Men det er da rigtigt at det bliver let at tale med medarbejderne i virksomheden om modellen, for den "ligner" det eksisterende system til forveksling.
En trænet objektorienteret systemudvikler ville have anlagt en langt mere antropomorfistisk synsvinkel (af antropomorfisme: at tillægge ting menneskelige egenskaber). De objekter der indgår i modellen skal kunne meget mere, de skal tillægges flere metoder end i ovenstående model. En mulighed er noget i retning af følgende:
* Medarbejder
- indeholder sit navn, adresse, bankkonto etc. og kan returnere dem på forespørgsel.
- indeholder en liste af timesedler.
- indeholder sine feriedage tilgode, og kan returnere dem på forespørgsel.
- kan returnere timesedlen for en given dag på forespørgsel.
- kan returnere sum af timetal fra timesedler på forespørgsel.
- kan generere og returnere en bankformular på forespørgsel.
- indeholder en virtuel metode til lønberegning.
* Fast medarbejder
- arver fra medarbejder.
- indeholder sin ugentlige løn.
- kan returnere den beregnede løn på forespørgsel (en konkretisering af den virtuelle lønberegning i medarbejder).
* Løs medarbejder
- arver fra medarbejder.
- indeholder sin timeløn.
- kan returnere den beregnede løn på forespørgsel (en konkretisering af den
virtuelle lønberegning i medarbejder).
* Timeseddel
- indeholder et antal timer og deres art (ordinær tid, overtid, ferie, sygdom).
- kan trykke sig selv.
* Bankformular
- kan trykke sig selv
* År-til-dato rapport
- kan generere og trykke en rapport på forespørgsel.
Denne model har langt mere objektorienteret appel i sig. Fx er det meget nemt at indføre andre aflønningstyper end fast løn og timeløn (akkord fx). Der skal ikke ændres noget i det eksisterende program, som blot skal udvides med en ny type medarbejder, der arver fra klassen Medarbejder. Problemet med denne model er imidlertid, at den slet ikke ligner det eksisterende system. Virksomhedens ledelse ville stramme op omkring ferieregnskabet og selve lønberegningen, og bliver jo nok skrækslagen ved at høre at programmøren påtænker at lave et system hvor det er medarbejderne selv der beregner lønnen og holder rede på sygedage og feriedage. Ideen om at have rapporter der beregner, formatterer og trykker sig selv er også meget unaturlig - sådan nogen plejer at blive beregnet, formatteret og trykt. Myten om at et objektorienteret program kommer til at ligne det eksisterende system mere end et procedureorienteret program har efter min mening ikke meget på sig. De to former er begge kunstige modeller af virkeligheden, hvor hovedvægten blot er lagt på forskellige datalogiske aspekter, nemlig datastrukturer i det objektorienterede design og dataprocesser i det procedureorienterede design.
Hvordan man skaber objektorienterede programmer med hovedet under armen går over min forstand. Jeg holder på at også objektorienteret programmering fordrer en intelligent og kreativ indsats for at kunne bruges til noget, ligesom al anden programmering. Men den objektorienterede programmeringsstil stiller nogle begreber og redskaber til rådighed, som gør det muligt at illustrere de principper man lærer om i software-engineering på en langt mere direkte og overbevisende måde end den procedureorienterede stil. Derfor er objektorienteret programmering efter min mening et godt pædagogisk værktøj i edb-uddannelser. Blot skal man passe på at eleverne ikke lærer om objektorientering for sent i uddannelsen; så har de tilegnet sig nogle uheldige vaner fra den procedureorinterede stil, som det er vanskeligt at komme til livs.